





Understanding Vertica: How Columnar Databases Can Transform Your Data Analytics
In the world of databases, there are different types that meet various needs and use cases. Relational databases, like PostgreSQL and MySQL, are widely known and used. However, another type of database, column-oriented databases such as Vertica, offer significant advantages in certain scenarios. In this article, we will explore the basics of relational databases, column-oriented databases, their differences, pros, cons, and use cases.
Introduction to relational databases (PostgreSQL, MySQL, etc.)
Relational databases store data in tables, organized in rows and columns. Each row represents a unique record, and each column represents an attribute. These databases use query languages, such as SQL, to insert, update, delete, and retrieve data. Some of the most popular relational databases include PostgreSQL, MySQL, Oracle, and SQL Server.
Differences between relational and column-oriented databases
The main difference between relational databases and column-oriented databases lies in how they store and organize data. While relational databases store data in rows, column-oriented databases do so in columns. This difference affects performance, compression, and efficiency in data retrieval.
Below is an example table with the following data:

Now, let's see how this data is stored in each type of database:


Column-oriented databases
This type of database emerged as a solution to address specific analysis and storage needs for large volumes of data. The concept of columnar databases was introduced by Edgar F. Codd, who also proposed the relational model for databases, in 1970. However, this type of database began to gain more popularity in the 2000s with the exponential growth of data generated by companies and the emergence of the big data era.
Column-oriented databases, like Vertica, store data in columns instead of rows. By storing column values together, greater data compression can be achieved due to the similarity of values within a column.
Here are some of the compression techniques used in columnar databases:
- Value encoding compression: This technique involves assigning shorter codes to the more frequent values in a column, reducing the required storage size. Huffman encoding is an example of this type of compression.
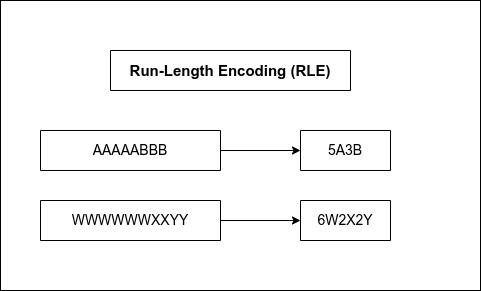
- Run-Length Encoding (RLE) compression: RLE compression is efficient when there are repeated sequences of values. Instead of storing each repeated value, the value and the number of times it is repeated are stored. For example, instead of storing "AAAAABBB," it would store "5A3B," which reduces the storage size.
- Delta-based compression: This technique involves storing the difference between consecutive values instead of the values themselves. For example, if a column contains the values 100, 101, 102, 103, they would be stored as 100, 1, 1, 1. Delta-based compression is particularly effective when the values in a column change slowly or follow a trend.

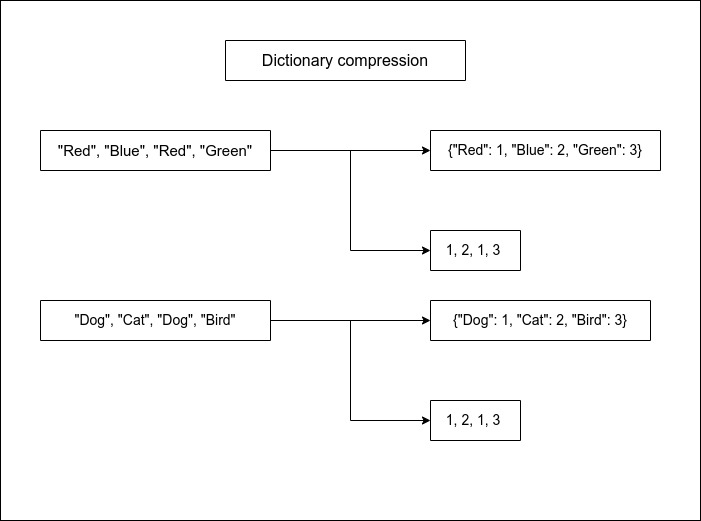
- Dictionary compression: In this technique, a unique dictionary of values is created for a column, and references to that dictionary are stored instead of the actual values. This is useful when there is a limited number of unique values in a column.
Compression in column-oriented databases allows for faster data reading, as less information is read from disk, resulting in better query performance. Additionally, compression reduces storage costs and improves overall system performance.
Benchmarking: Performance Test in PostgreSQL vs Vertica
In this section, we will provide results from a performance test that we conducted using a test table. The table consists of 10 million people records, including id, name, and age. Although the table is relatively simple, it will serve to see the difference in performance between both databases for certain queries.
Average age calculation for people over 35 years old


Count of repeated names


Search for all people aged 37


After running these queries in both PostgreSQL and Vertica, we plot the execution times in a bar chart. Here, the Y-axis represents the execution time in milliseconds, and the X-axis represents each query.

As we can see from the chart, Vertica outperforms PostgreSQL in all the queries performed, especially in the queries that involve data aggregation and pattern searching, like the calculation of average age and grouping by age.
It is important to mention that this performance gap would increase as the size and complexity of the data increase. Columnar databases like Vertica are especially efficient at handling large volumes of data and performing complex analytical operations.
Note: Execution times may vary depending on hardware configuration and other factors.
Pros and cons of each type of database
Relational databases:
Pros:
- Widely adopted and compatible with a variety of applications and tools.
- Easy to understand and work with, thanks to their tabular structure.
- Good performance in transactions and queries involving multiple attributes.
Cons:
- Not as efficient in analytical queries and data aggregations.
- Can suffer performance issues when tables become very large.
Column-oriented databases (Vertica):
Pros:
- Greater data compression, reducing storage space and improving performance.
- Excellent performance in analytical queries and data aggregations.
- Horizontal scalability, making growth and expansion easier.
Cons:
- Less suitable for transactions. Vertica is optimized for analytical queries and may not be the best choice for applications with a high volume of read and write transactions (OLTP) compared to traditional relational databases.
- Less compatibility with tools and applications compared to relational databases.
Use cases
Relational databases are ideal for:
- Web and mobile applications with real-time transactions.
- Content management systems and e-commerce
- Small and medium-sized businesses with less intensive data management needs.
Column-oriented databases (Vertica) are ideal for:
- Analyzing large volumes of data and aggregate queries.
- Processing time-series data, such as sensor data or event logs.
- Business intelligence applications and data-driven decision making.
- Large organizations and enterprises with intensive data analysis needs.
Some companies using Vertica
Uber
Uber uses the advanced analytics platform Vertica to manage and analyze data from millions of rides and food deliveries on their platform. With Vertica's help, Uber can quickly measure the success of new services and swiftly identify root causes of data anomalies. Faced with the challenge of exponential growth in ride and delivery volume, Uber implemented a strategy of partial replication of Vertica clusters, achieving significant savings in disk consumption of over 30%, while maintaining the same level of computational scalability and database availability. This optimization allowed Uber to balance the load across clusters, improving uptime and reducing failures.
Philips
Philips is using Vertica to move towards zero unplanned downtime of medical imaging systems through remote monitoring and predictive analytics. Vertica allows Philips to collect and process data from the devices to identify potential problems, reduce the likelihood of costly downtime, and minimize the impact on patients. Additionally, Vertica facilitates continuous data-driven innovation with integrated teams of subject matter experts, data scientists, and business stakeholders.
NSoft
NSoft chose Vertica for its high performance, scalability, and maturity to meet their needs. Vertica allowed NSoft to implement a data warehouse solution without disrupting the core product development. Vertica also fully integrated the new system with the existing one and allowed NSoft to expand without affecting product plans. Vertica's ease of integration and flexible deployment resulted in an improvement in data analysis workflows, providing NSoft's customers and partners with near real-time reports.
Simpli.fi
The Simpli.fi platform uses Vertica to allow marketers to extract value from unstructured data in real time in real-time bidding (RTB) advertising exchanges. Advertisers can target, bid, optimize, and report at the data element level.
Adform
Adform uses the Vertica advanced analytics platform to provide its clients with sophisticated control, management, and reporting capabilities that maximize their return on investment in programmatic advertising.
Optimal Plus
Optimal Plus chose Vertica, a market leader in column storage compressed databases, for its remarkable performance in structured data and its ability to effectively scale to meet future requirements. Vertica allowed Optimal Plus to load and process data in the database at significantly faster speeds than with its legacy database, thereby improving its predictive algorithms and ensuring maximum uptime of plant assets.
World Wide Technology (WWT)
WWT uses Vertica to become a more sophisticated organization in terms of reporting. Vertica enables WWT to report a wide variety of metrics, from defects and incident reports to complex dashboards evaluating the quality of the tests, test coverage, user errors, severity of reported issues, and more. This scalable solution also helps WWT obtain a more granular and real-time view of their velocity.
Conclusion:
While relational databases are great for real-time transactions and applications with multiple attributes, column-oriented databases like Vertica are ideal for analytical queries and processing large volumes of data. The choice between the two will depend on your specific needs and use cases.
Does your current system meet the requirements to take advantage of Vertica?
After understanding the differences between relational and columnar databases like Vertica, take a moment to reflect on the systems you've worked with. Are they meeting your requirements? Could implementing Vertica provide greater benefits? If you have any doubts or are interested in learning more, don't hesitate to reach out to us. Our team is always here to help you with any questions or concerns you may have.

Contact Us
Send us a message and we will contact you shortly -




